|
Email: wu.kathrina[at]gmail.com / Google Scholar / CV / Github /Linkedin /OpenReview I am currently a researcher at AI Theory Lab of Huawei Noah's Ark Lab (Hong Kong), working closely with Dr. Zhenguo Li and Dr. Enze Xie . I obtained my Ph.D. degree at Computer Science and Engineering department of Hong Kong University of Science and Technology (HKUST) at June 2023 , supervised by Prof. Qifeng Chen . Prior to this, I got my Bachelor's degree from Wuhan University in 2018. I have research experience in computational photography, image/video synthesis, 3D generative models, and neural rendering. And I'm conducting research in AIGC in 2D/3D/Video.
|

|
|
Researcher, Huawei Noah's Ark Lab, Aug.2023 - now.
|
|
* indicates joint authors |
|
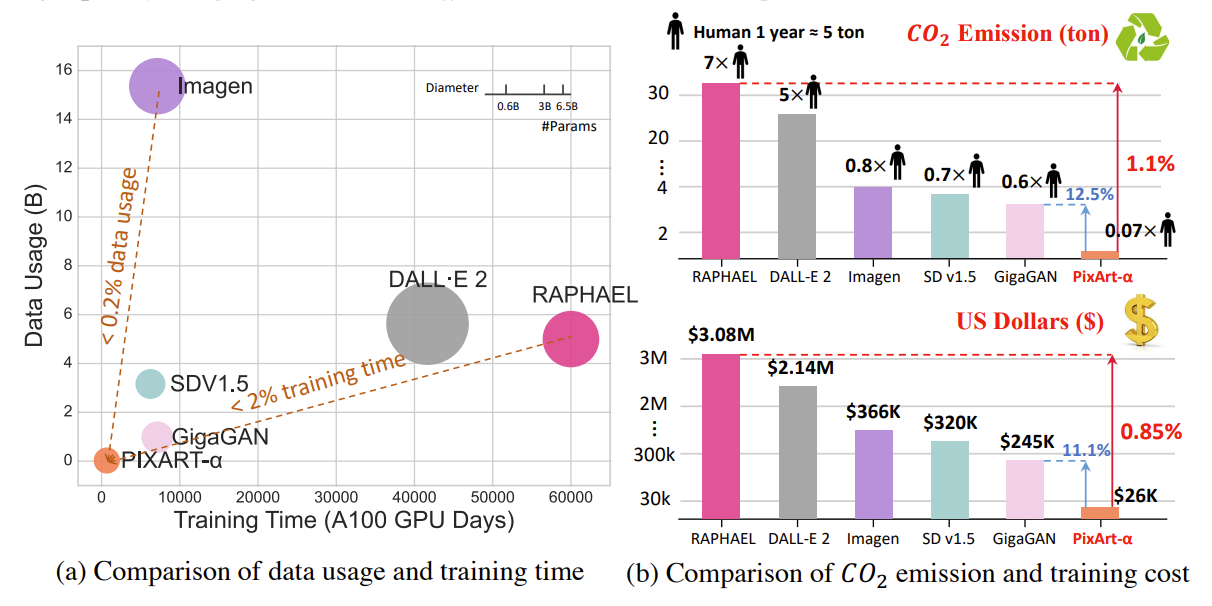
Junsong Chen*, Chongjian Ge*, Enze Xie*†, Yue Wu*, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, Zhenguo Li ECCV, 2024 [PDF] [Code] [机器之心] |
|
|
Junsong Chen, Yue Wu, Simian Luo, Enze Xie, Sayak Paul, Ping Luo, Hang Zhao, Zhenguo Li Tech Report, 2024 [PDF] |
|
|
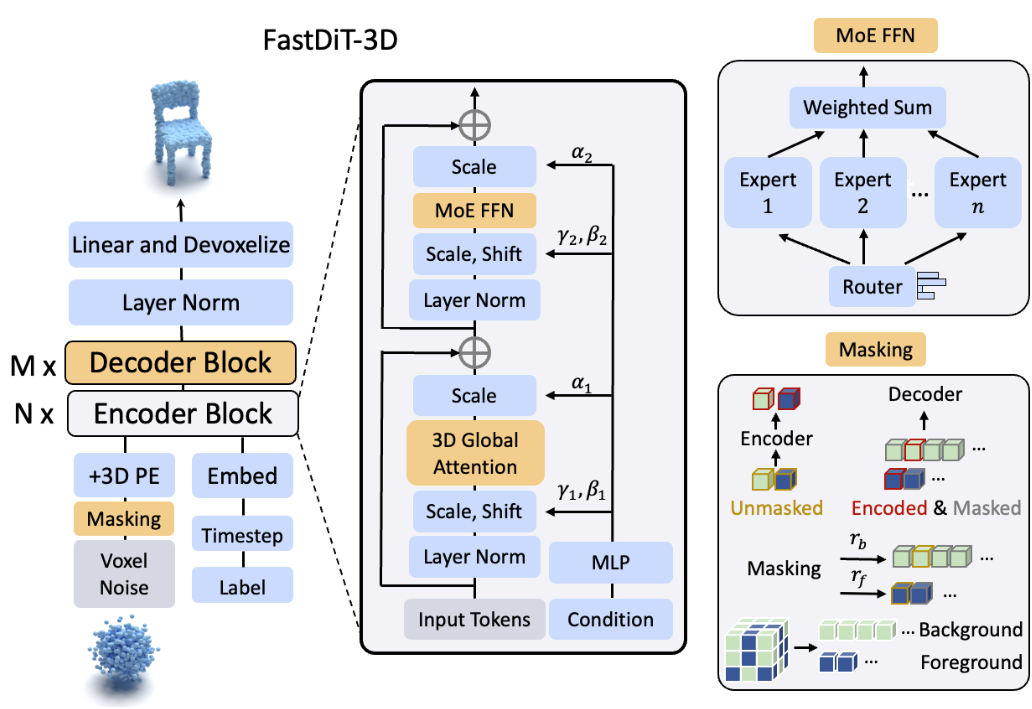
Junsong Chen*, Jincheng Yu*, Chongjian Ge*, Lewei Yao*, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, Zhenguo Li ICLR Spotlight, 2024 [PDF] [Arxiv] [Project] [Code] [机器之心] |
|
Tianwei Xiong, Yue Wu, Enze Xie, Yue Wu, Zhenguo Li, Xihui Liu Preprint, 2024 [Project] |
|
|
Xiaoyan Cong, Yue Wu, Qifeng Chen, Chenyang Lei CVPR, 2024 |
|
|
Shentong Mo, Enze Xie, Yue Wu, Junsong Chen, Matthias Nießner, Zhenguo Li ECCV, 2024 [Project] [Arxiv] |
|
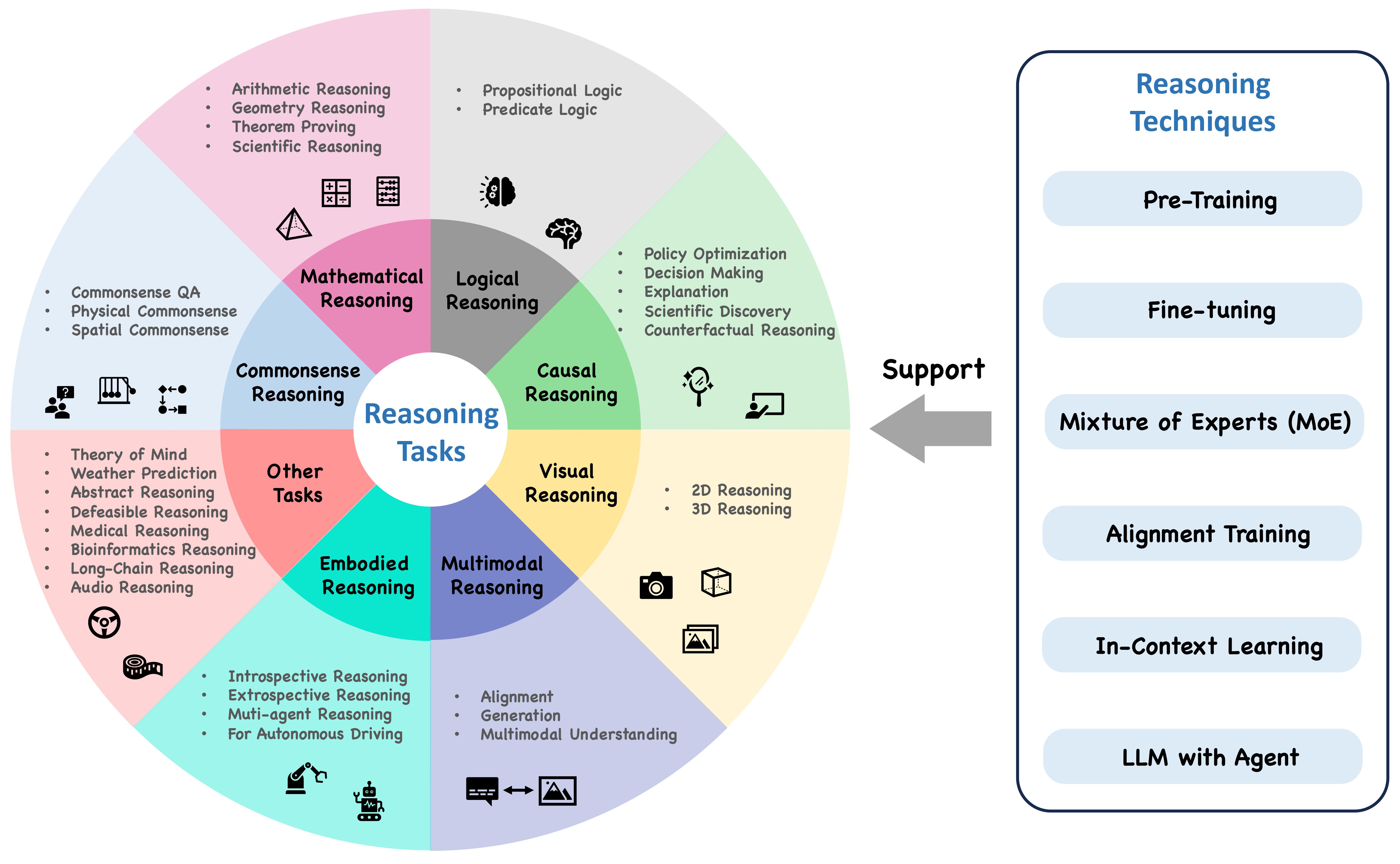
Jiankai Sun, Chuanyang Zheng, Enze Xie, Zhengying Liu, Ruihang Chu, Jianing Qiu, Jiaqi Xu, Mingyu Ding, Hongyang Li, Mengzhe Geng, Yue Wu, Wenhai Wang, Junsong Chen, Xiaozhe Ren, Jie Fu, Junxian He, Wu Yuan, Qi Liu, Xihui Liu, Yu Li, Hao Dong, Yu Cheng, Ming Zhang, Pheng Ann Heng, Jifeng Dai, Ping Luo, Jingdong Wang, Jirong Wen, Xipeng Qiu, Yike Guo, Hui Xiong, Qun Liu, and Zhenguo Li Preprint, 2023 [Project] [Arxiv] |
|
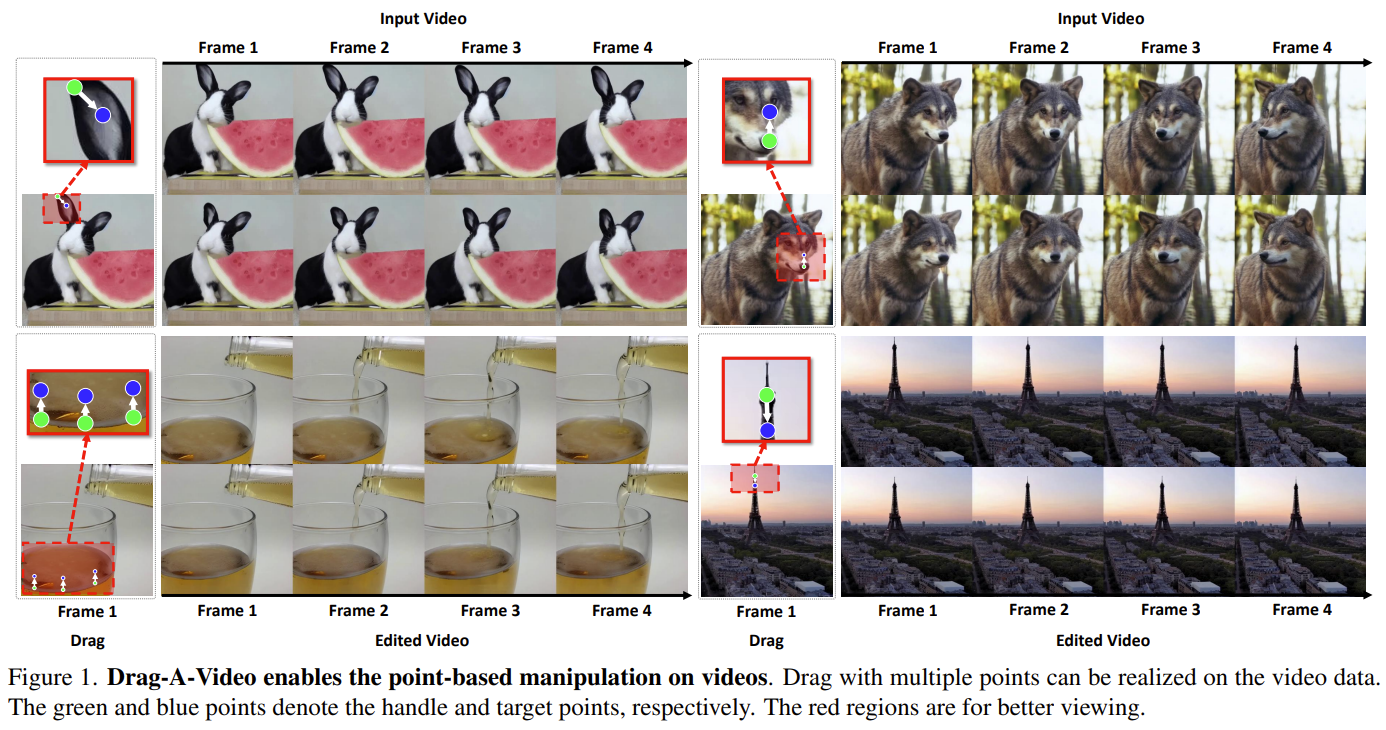
Yao Teng, Enze Xie, Yue Wu , Haoyu Han, Zhenguo Li, Xihui Liu Preprint, 2023 [Arxiv] [Project] |

|
Yue Wu*, Sicheng Xu*, Jianfeng Xiang, Fangyun Wei, Qifeng Chen, Jiaolong Yang, Xin Tong SIGGRAPH Asia, 2023 [PDF] [Project] [Code] [新智元] |
|
|
Yue Wu, Yu Deng, Jiaolong Yang, Fangyun Wei, Qifeng Chen, Xin Tong Neural Information Processing Systems (NeurIPS) (Spotlight), 2022 [PDF] [Project] [BibTeX] [Code] |

|
Qiang Wen, Yue Wu, Qifeng Chen IEEE International Conference on Robotics and Automation (ICRA), 2023 [PDF] [Code] [极市平台] |

|
Guotao Meng*, Yue Wu*, Qifeng Chen IEEE International Conference on Robotics and Automation (ICRA), 2023 [arXiv] |
|
|
Yue Wu, Qiang Wen, Qifeng Chen IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [PDF] [Project] [Code and Results] [BibTeX] |

|
Yue Wu*, Guotao Meng*, Qifeng Chen International Conference on Computer Vision (ICCV), 2021 [PDF] [arXiv] [Project] [BibTeX] |

|
Chenyang Lei *, Yue Wu*, Qifeng Chen Preprint 2021, [arXiv] |

|
Yue Wu, Rongrong Gao, Jaesik Park, Qifeng Chen Computer Vision and Pattern Recognition Conference (CVPR), 2020 [PDF] [arXiv] [Code and Result] [BibTeX] |
|
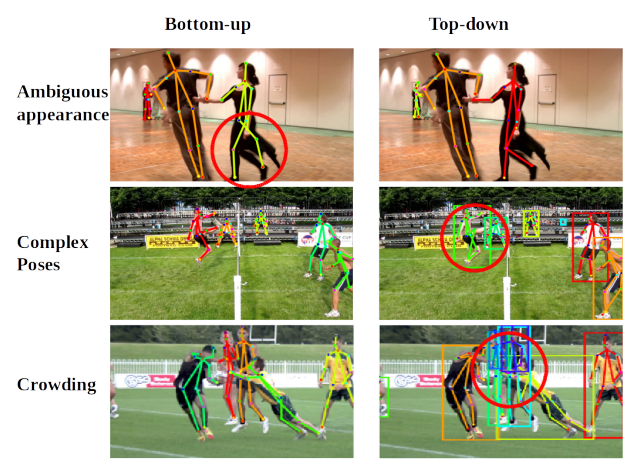
Sheng Jin, Xujie Ma, Zhipeng Han, Yue Wu, Wei Yang, Wentao Liu, Chen Qian, Wanli Ouyang International Conference on Computer Vision (ICCV Workshops), 2017 [PDF] Ranked 2nd Places in ICCV Posetrack Challenge |
|
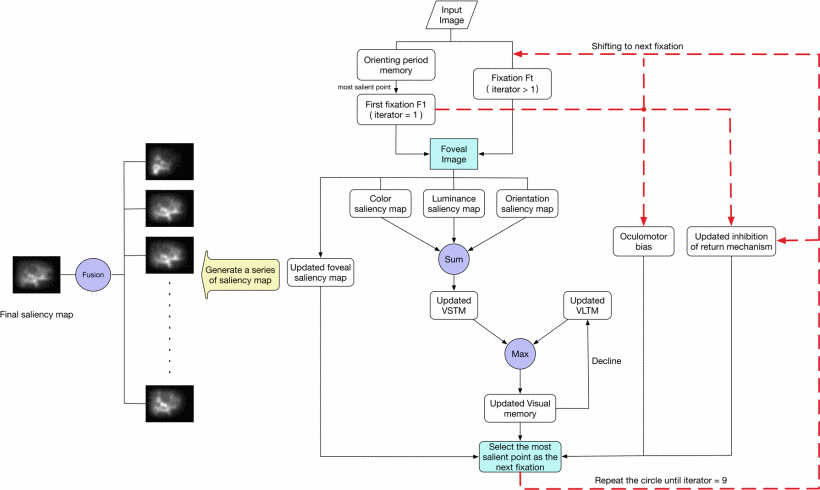
Yue Wu, Zhenzhong Chen ICME, 2017 [PDF] |
|
COMP5411: Computer Graphics, 2019
|
|
HKUST RedBird Academic Excellence Award, HKUST
|
|
Reviewer for ECCV 2022, CVPR 2022/2023/2024, ICRA 2023, JMLR
|