AniPortraitGAN:
Animatable 3D Portrait Generation from 2D Image Collections
SIGGRAPH Asia 2023
- Yue Wu 1*
- Sicheng Xu 2*
- Jianfeng Xiang 3,2
- Fangyun Wei 2
- Qifeng Chen 1
- Jiaolong Yang 2♦
- Xin Tong 2
- 1 Hong Kong University of Science and Technology
- 2 Microsoft Research Asia
- 3 Tsinghua Unviersity
- *: Equal contribution
- ♦: Corresponding author and project lead



AniPortraitGAN is a new 3D-aware GAN that can generate diverse virtual human portraits (512x512) with explicitly controllable 3D camera viewpoints, facial expression, head pose, and shoulder movements. It is trained on unstructured single image collections without any 3D or video data.
Abstract
Previous animatable 3D-aware GANs for human generation have primarily focused on either the human head or full body. However, head-only videos are relatively uncommon in real life, and full body generation typically does not deal with facial expression control and still has challenges in generating high-quality results. Towards applicable video avatars, we present an animatable 3D-aware GAN that generates portrait images with controllable facial expression, head pose, and shoulder movements. For this new task, we base our method on the generative radiance manifold representation and equip it with learnable facial and head-shoulder deformations. A dual-camera rendering and adversarial learning scheme is proposed to improve the quality of the generated faces, which is critical for portrait images. A pose deformation processing network is developed to generate plausible deformations for challenging regions such as long hair. Experiments show that our method, trained on unstructured 2D images, can generate diverse and high-quality 3D portraits with desired control over different properties.
Method overview
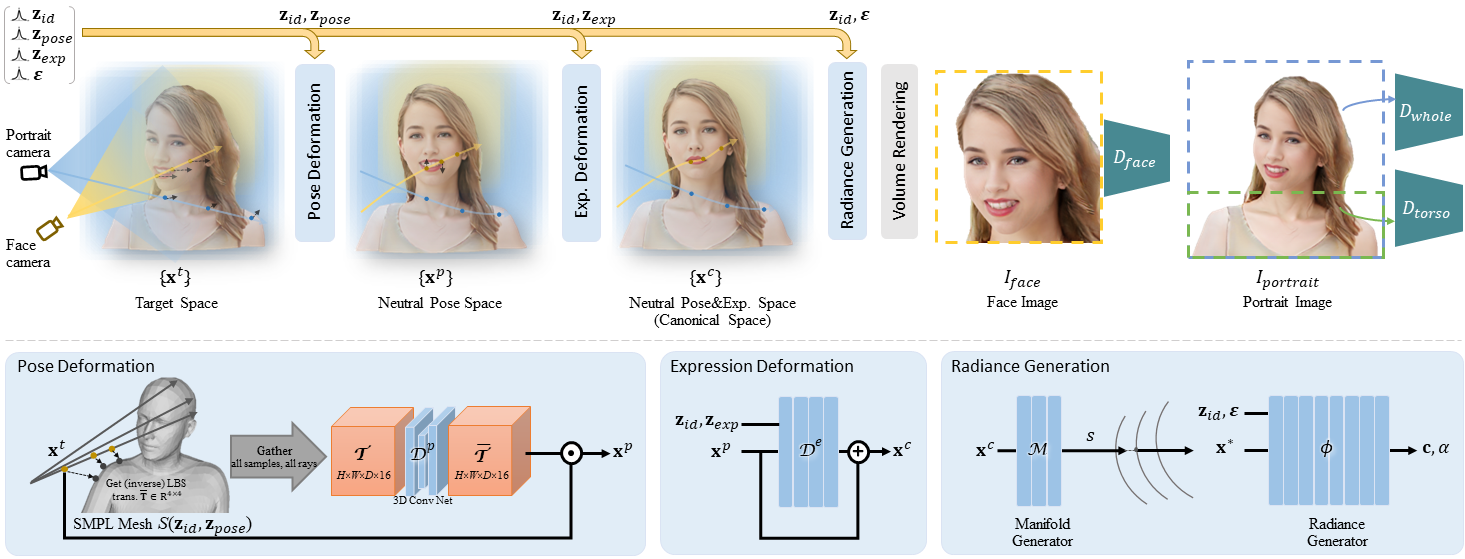
Top: the pipeline of our controllable 3D-aware portrait GAN. For training, we apply a dual-camera rendering scheme with two images separated rendered and three discriminators employed. Bottom: the deformation and radiance generation modules
Uncurated random generation results
Virtual talking charactors driven by real videos
Full supplimentary video
Ethics and responsible AI considerations
This work aims to design an animatable 3D-aware human portrait generation method for the application of photorealistic virtual avatars. It is not intended to create content that is used to mislead or deceive. However, like other related human image generation techniques, it could still potentially be misused for impersonating humans. We condemn any behavior to create misleading or harmful contents of real person, and are interested in applying this technology for advancing 3D- and video-based forgery detection. Currently, the images generated by this method contain visual artifacts that can be easily identified. The method is data driven, and the performance is affected by the biases in the training data. One should be careful about the data collection process and ensure unbiased distrubitions of race, gender, age, among others.
Citation
@inproceedings{yue2023aniportraitgan,
title={AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections},
author={Wu, Yue and Xu, Sicheng and Xiang, Jianfeng and Wei, Fangyun and Chen, Qifeng and Yang, Jiaolong and Tong, Xin},
booktitle={SIGGRAPH Asia 2023 Conference Proceedings},
year={2023}
}
Related projects: GRAM, GRAM-HD, AniFaceGAN, MPS-NeRF, DiscoFaceGAN
The website template was adapted from GRAM.